PUBLIKATIONEN VON HATHITRUST HERUNTERLADEN
Der HathiTrust und sein digitaler Zugang
Der HathiTrust wurde im Jahre 2008 von 12 us-amerikanischen Universitäten und 11 Bibliotheken, welche im Bibliotheksverbund der University of Carolina zusammengefasst sind, gegründet. Diese Einrichtungen werden von dem HathiTrust als Partnerinstitutionen bezeichnet. Hathi bedeutet „Elefant“ und ist als eine Anspielung auf das gute Gedächtnis dieser Tiere zu verstehen. Daher ist auch ein Elefant auf dem Log zu sehen.
{kind=link}
Der Trust beherbergt mehr als 17 Millionen Digitalisate, wozu auch Bücher von Google Books und dem Internet Archive gehören. Frei zugänglich sind weltweit nur die Publikationen, deren Erscheinen mehr als 140 Jahre zurückliegt. Um digitale Bücher, die bis zum Jahr 1922 veröffentlicht wurden und in den USA public domain sind, mit dem Computer einzusehen, muss das Gerät eine IP-Adresse aus den USA besitzen, da sonst das Geoblocking den Zugang verhindert.
Was ist eine IP-Adresse?
Jeder Computer benötigt eine IP-Adresse, damit er identifiziert werden und Daten an ein anderes Gerät schicken kann. IP steht dabei für Internet Protocol, welcher ein weltweiter Netzstandard ist. Sobald sich der Router des Computers mit dem Internet verbindet, bekommt er vom Internetanbieter, dem Provider, eine IP-Adresse zugewiesen. Über diese IP-Adresse kann der Provider dann auch nachverfolgen, wer wann was im Internet gesucht und/oder heruntergeladen hat. Diese von außen sichtbare Adresse kann über Programme wie etwa Dein Ip Chek (https://www.dein-ip-check.de/) ermittelt werden. Sie liefern auch Hinweise auf den Standort, der dann etwa von Suchmaschinenbetreibern als Parameter benutzt wird. So liefert die Suche nach einer Münzenhandlung vorwiegend Ergebnisse aus der eigenen Umgebung, sofern kein bestimmter Ort bei der Suche angegeben wurde.
Die Ländersperre
Über Programme für Geolocating (Ortsbestimmung) wird erkannt, ob die IP-Adresse zu einem Gerät gehört, welches aus dem Land stammt, für welches die Nutzung gewollt ist. Um außerhalb der Vereinigten Staaten von Amerika eine us-amerikanische IP-Adresse zu erhalten, kann man entweder in Google Chrome oder Mozilla Firefox ein Add-on installieren oder den Dienst eines Proxy VPN Anbieters nutzen. Diese Vorgehensweise wäre dann illegal, wenn es sich bei der Ländersperre um eine wirksame technische Schutzmaßnahme gemäß § 95a des Urheber Gesetztes handeln würde. Unter Suchbegriffen wie etwa „US IP bekommen“ lassen sich im Internet eine Vielzahl von Möglichkeiten finden, um eine IP-Adresse der USA zu erhalten.
Hathi Download Helper
Der download der zugänglichen Publikationen erfolgt mit dem Programm Hathi Download Helper, das von der Firma Sourceforge kostenlos zur Verfügung gestellt wird (https://sourceforge.net/projects/hathidownloadhelper/).
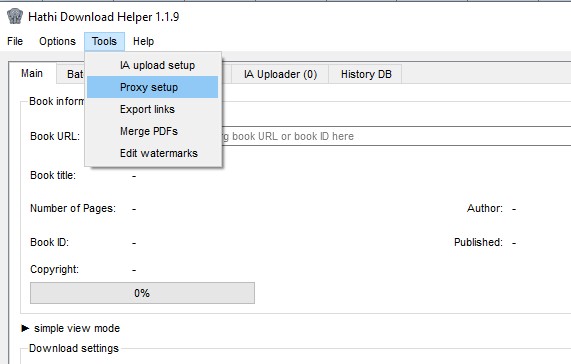
Die aktuelle Version 1.1.9 wurde am 17. Februar 2020 veröffentlicht. Das Programm läuft unter Windows. Nach Angaben von Sourceforce wurde der Download Helper aber auch mit den Betriebssystemen Win 7 Pro, Win 10 Pro, Mac OS 10.10 Yosemite, Mac OS 10.15 Catalina, Ubuntu 14.04-18.04 getestet. Im Lieferumfang ist eine automatische Proxy-Einstellung (Tools/ Proxy setup), die aber nach meinen Erfahrungen sehr instabil ist und nicht zufriedenstellend läuft. Nachdem das Programm heruntergeladen und installiert wurde, erscheint das Bild eines Elefanten als Programmsymbol auf dem Screen.
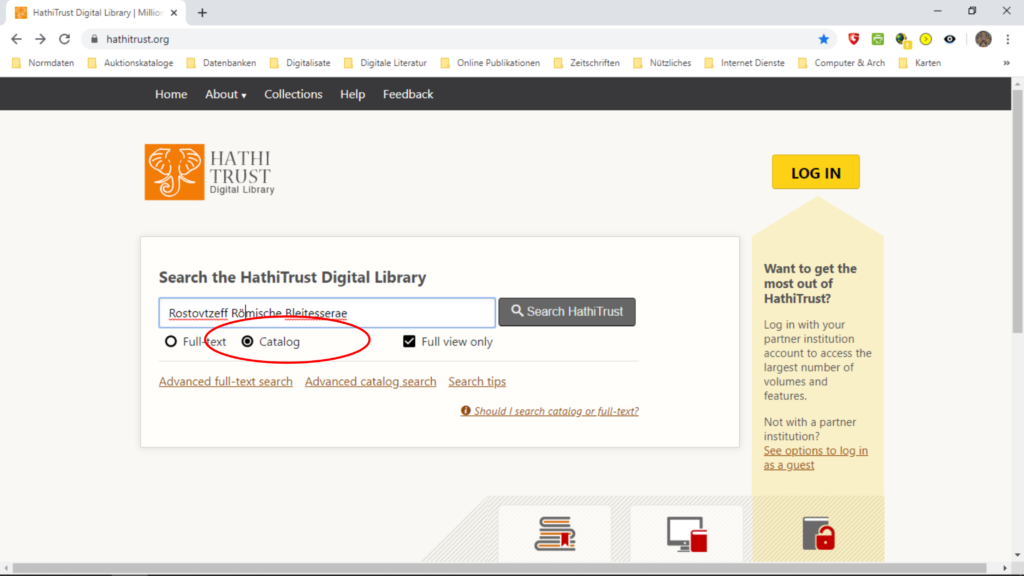
Zunächst wird die us-amerikanische IP-Adresse aktiviert, danach die Seite von HathiTrust geöffnet ….
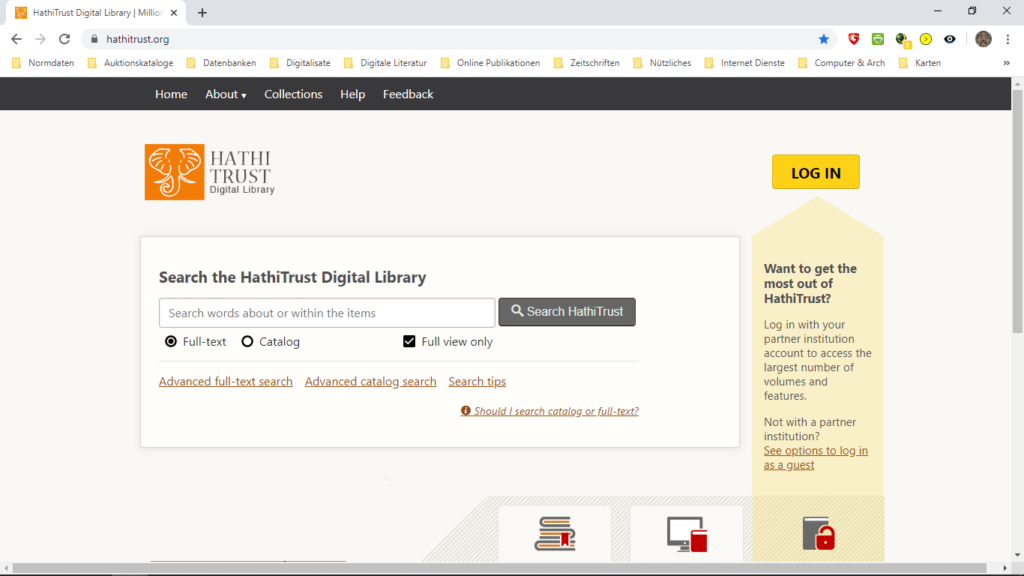
.… und im Suchschlitz das gewünschte Buch vermerkt. In diesem Fall ist es „Rostovtzeff Römische Bleitesserae“. Es wird „Catalog“ markiert, um nur das Buch zu suchen und nicht alle Einträge im “Full-text”, die sich auf diese Publikation beziehen.
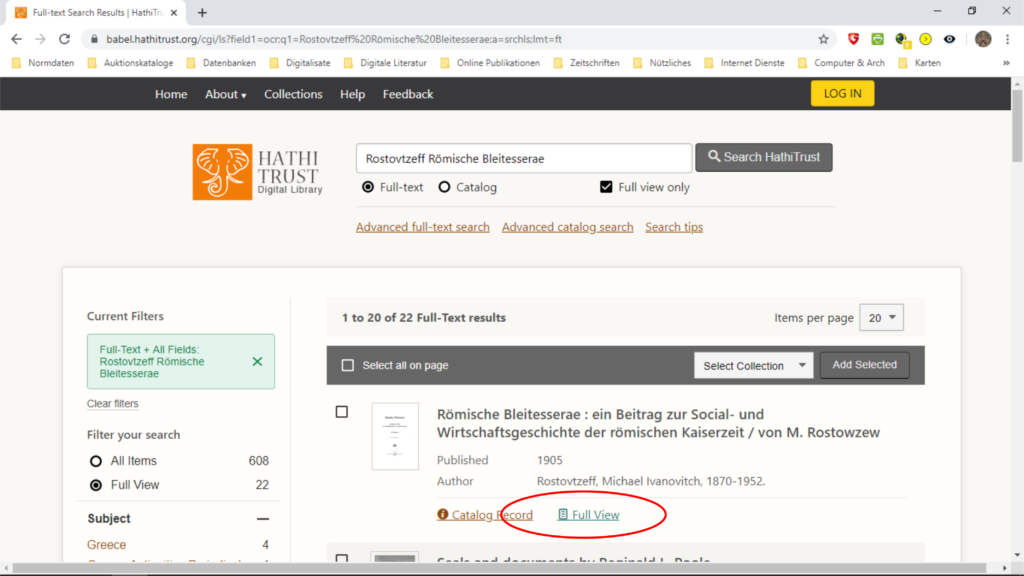
Nachdem das Buch aufgeführt wurde, wird „full view“ angewählt ….
…. und die Publikation wird angezeigt.
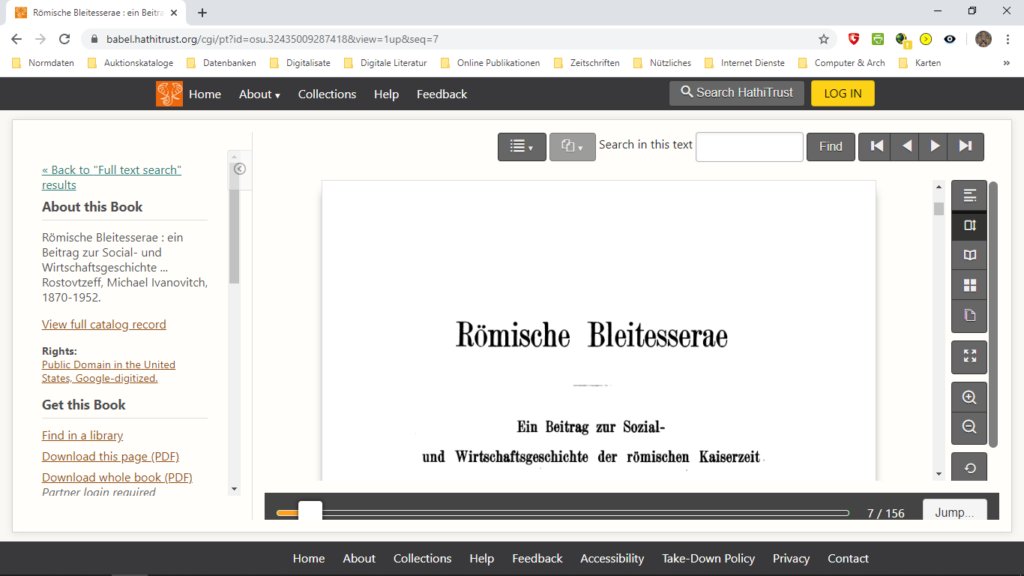
Hiernach muss in der linken Spalte nach unten gescrollt werden, bis der permanente link sichtbar ist. Dieser wird durch Anklicken in die Zwischenablage kopiert.
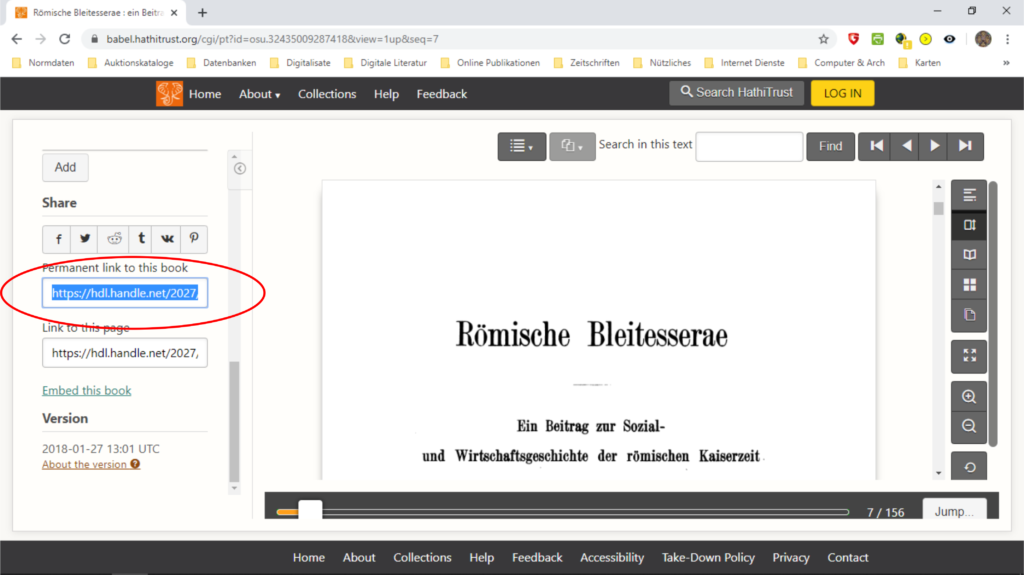
Nun wird der Hathi Download Helper geöffnet, wozu das Icon auf dem Bildschirm angeklickt wird. Das Programmfenster öffnet sich.
Download als pdf
In der Standardeinstellung wird die Publikation als pdf mit durchsuchbarem Text heruntergeladen (searchable pdf). Weiter unten wird noch auf die Möglichkeit des Downloads von „images“ eingegangen. Wichtig ist die Markierung bei „merge pdf“ im unteren Teil des Fensters. Sind alle Seiten gespeichert, sollten diese automatisch zu einer Datei verbunden werden (merge).
In den oberen Bereich, welcher der „Book information“ vorbehalten ist, wird in den Schlitz die Adresse des permanenten Links aus der Zwischenablage eingefügt.
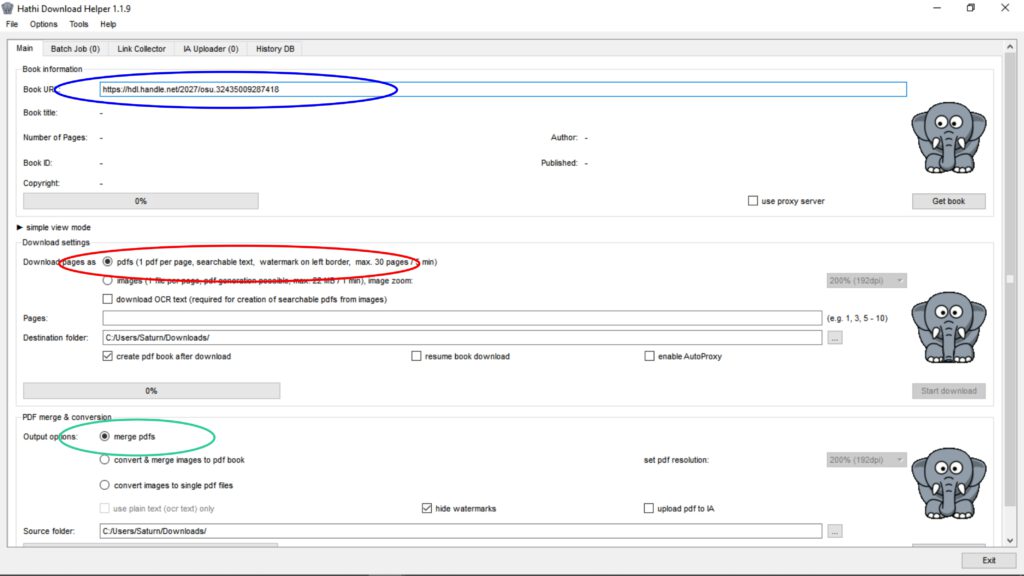
Die Daten werden in dem für den Download vorgesehenen Ordner abgelegt. Unter Source folder kann jedoch auch ein anderes Verzeichnis eingegeben werden. Abschließend wird die Taste „Get book“ durch Anklicken aktiviert.
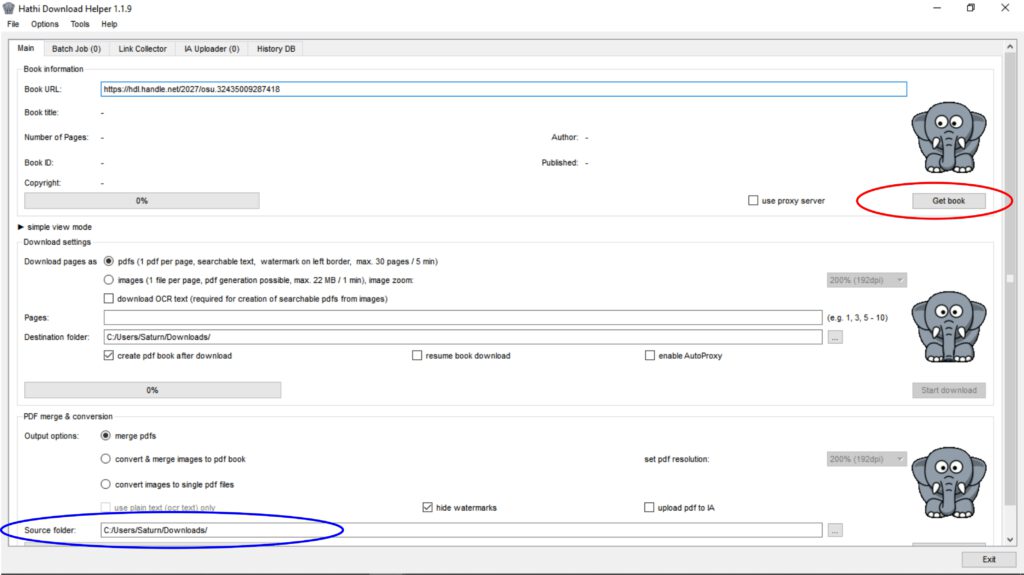
Nun wird das Buch geladen, was durch ein grünes Band und Augenbewegungen des Elefanten angezeigt wird.
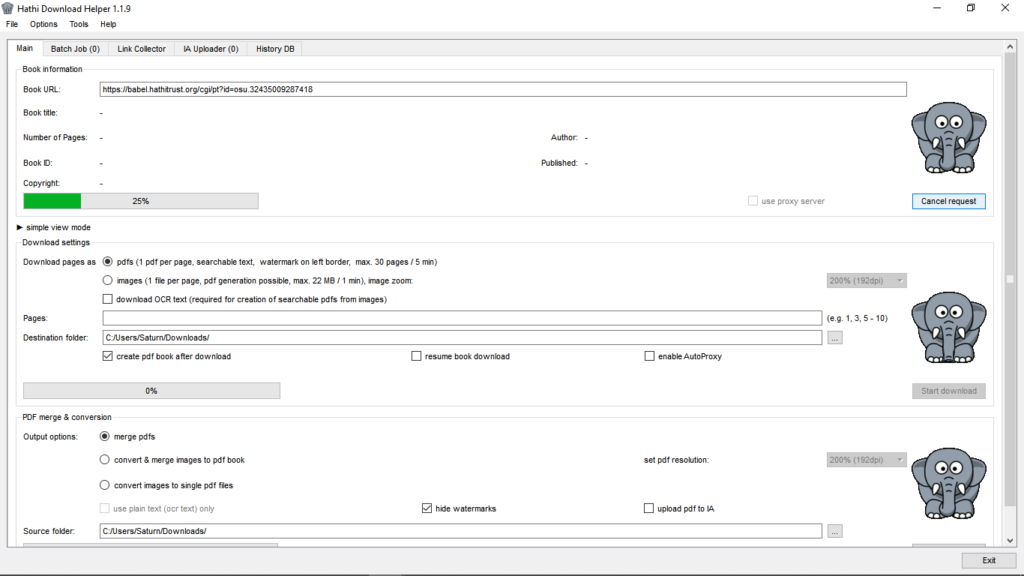
Ist das Buch geladen, beginnt der Download, wobei der Rüssel des mittleren Elefanten Saugbewegungen ausführt und seine Augen kullern. Der Download des pdf-Dokuments läuft in mehreren Abschnitten, die jeweils durch eine fünfminütige Unterbrechung voneinander getrennt sind. Innerhalb jedes Abschnitts können maximal 30 Seiten heruntergeladen werden. Je nach Umfang der Publikation und der Geschwindigkeit der Internet-Verbindung, kann das Herunterladen daher mehrere Stunden lang andauern. Der zeitliche Aufwand kann jedoch verkürzt werden, indem man das Programm mehrfach öffnet und mehrere Publikationen gleichzeitig downloaded. Es ist aber ratsam zu prüfen, ob die entsprechende Schrift nicht auch an anderer Stelle, z.B. dem Internetarchive, verfügbar ist.
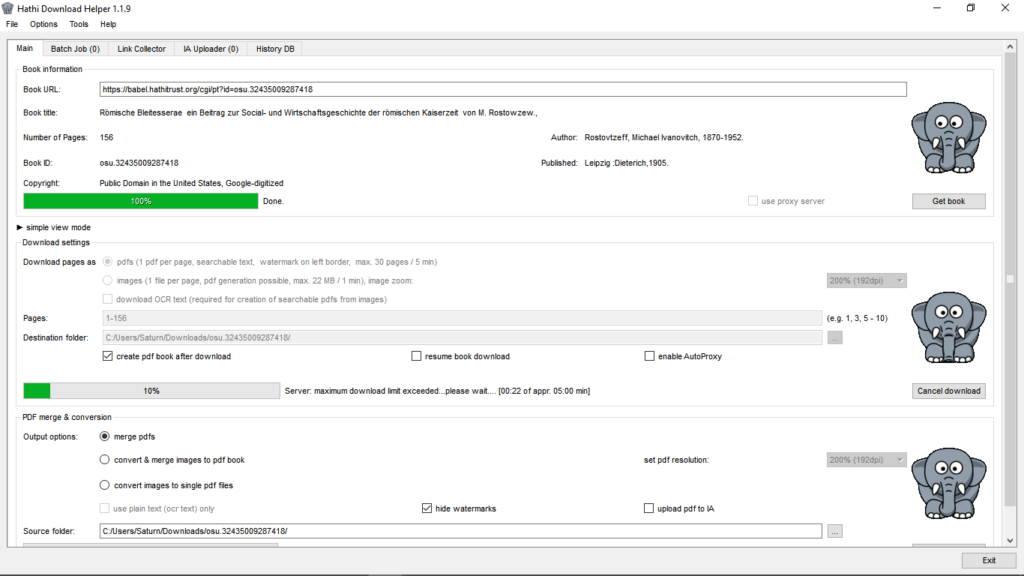
Nachdem das Buch vollständig heruntergeladen wurde, sollte sich automatisch der Explorer öffnen, …..
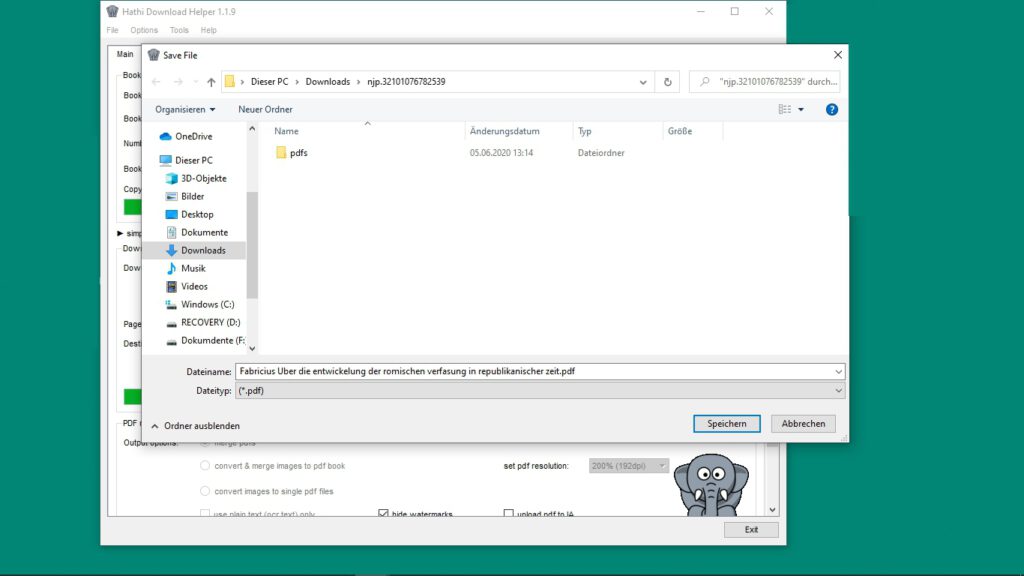
…. um die fertige pdf-Datei in dem von dem Browser für den Download vorgesehenen oder selbständig ausgewählten Ordner abzuspeichern. Wie Sie gegebenenfalls die vorgegebene Einstellung in ihrem Browser ändern können, erfahren Sie im Help support der einzelnen Anbieter (Microsoft Edge, Goolge Chrome, Mozilla Firefox).
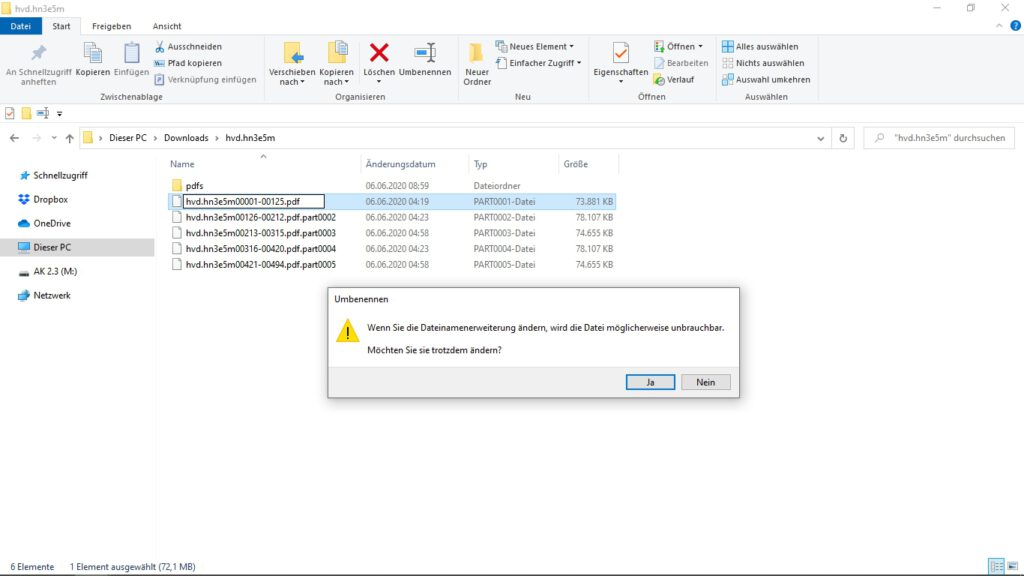
Es kann jedoch vorkommen, dass die Zusammenführung der Dateien zu einem pdf nicht vollständig von statten gegangen ist. Im Verzeichnis sind dann eine Reihe von Dateien mit der Endung „part“ und einer fortlaufenden Nummer zu sehen, die nun selbständig zusammengeführt werden müssen.
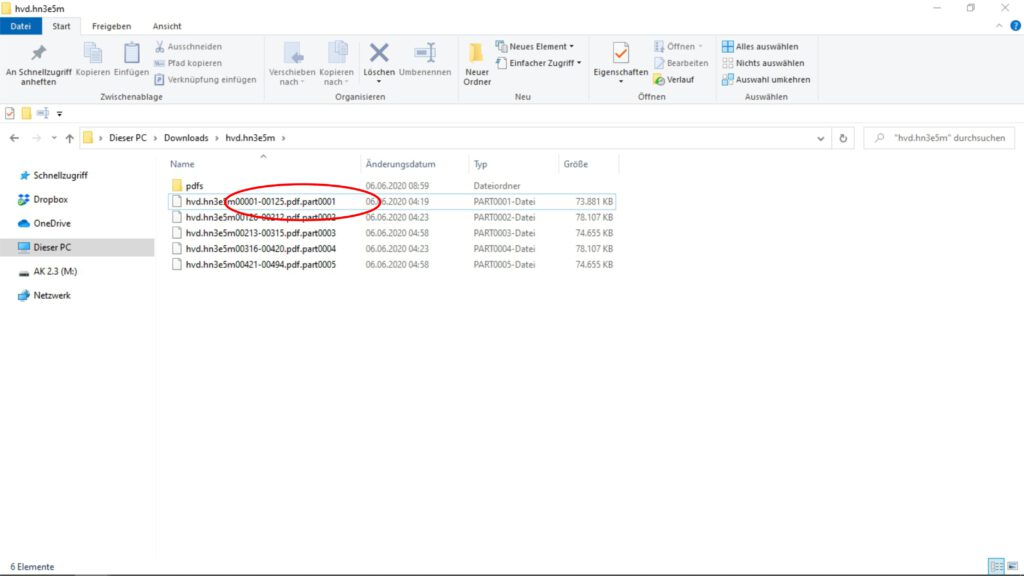
Dazu wird diese Endung bei allen Dateien in dem Verzeichnis gelöscht, so dass am Ende des Dateinamens nur noch *.pdf erscheint. Bevor die Endungen gelöscht werden können, erscheint in einem Fenster die Warnung: „Wenn Sie die Dateinamenerweiterung ändern, wird die Datei möglicherweise unbrauchbar. Möchten Sie sie trotzdem ändern?“ Dieser Hinweis kann ignoriert und das Fenster durch Drücken der Taste „ja“ geschlossen werden.
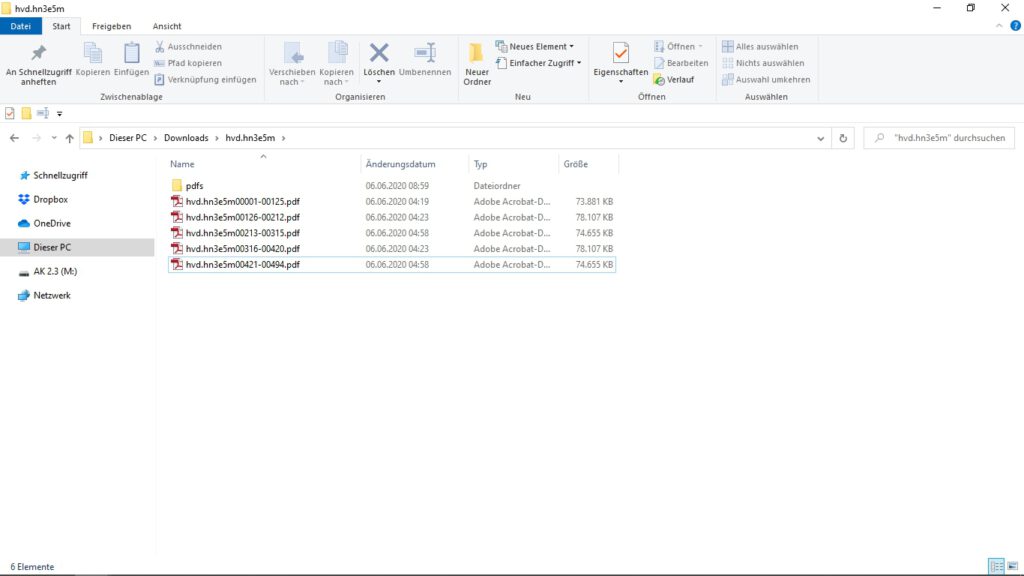
Alle Dateien liegen nun als pdf vor und können verbunden werden.
{kind=link}
Die Umwandlung kann etwa mit Adobe Acrobat Pro (heute Adobe DC) erfolgen. Günstiger ist PDF24 Creator, eine Freeware der Firma geek Software; allerdings ist es vergleichsweise zeitaufwendig, mehrere und größere pdf-Dateien zusammenzufügen. Mit dieser Software können die Seiten auch beschnitten und gedreht werden.
Achtung: PDF24 Creator kann leicht mit PDF-Creator oder PDFCreator verwechselt werden! Von der Benutzung beider Programme rate ich dringend ab. Ich empfehle auch Programme generell nur von der Seite des Herstellers herunterzuladen.
Einen Einblick in die Leistungsfähigkeit verschiedener Programme gibt eine Studie der Stiftung Warentest, die im Jahre 2020 eine Reihe käuflicher Pdf-Editoren untersuchte.
Bei der Arbeit von Rostovtzeff handelt es sich um eine Digitalisat von Google. Daher sind die Tafeln vergoogelt, d.h. die Abbildungen sind nachträglich bewusst teilweise verdunkelt und unbrauchbar gemacht worden.

Frontispiz und Tafel II.
Download als image
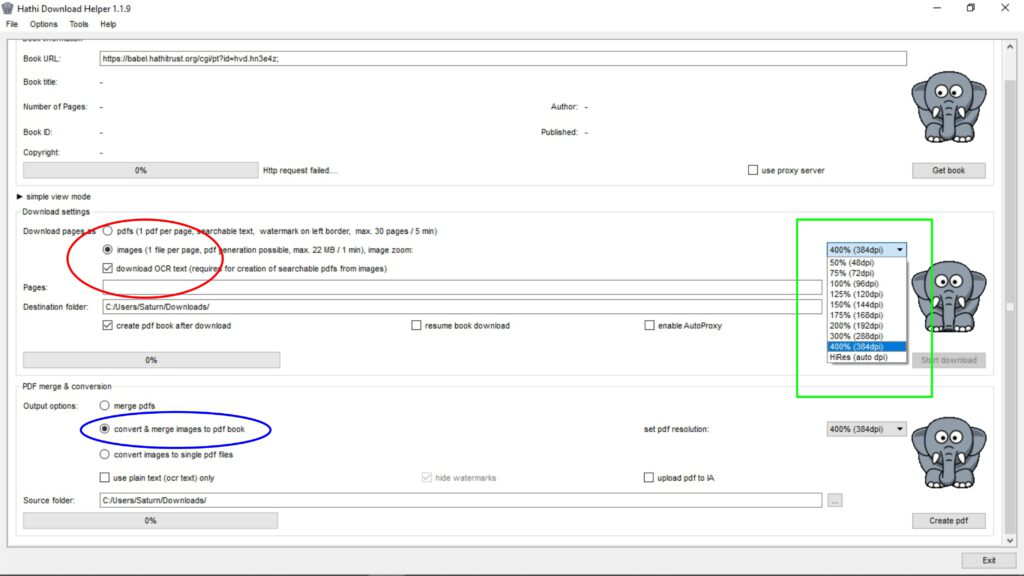
Statt als pdf kann die gewünschte Publikation mit HathiTrust Download Helper auch als „image“ heruntergeladen werden, wobei jede Seite als png-Graphik abgelegt wird. Dies geht wesentlich schneller, da pro Minute maximal 22MB an Daten übertragen werden können, was in etwa 30 DIN A-4 Seiten ohne Abbildungen entspricht. Doch handelt es sich hier um ein image only pfd, d.h. der Text ist nicht durchsuchbar. Für den Download wird im Feld „image ( … )“ angewählt. Dabei wird in dem Kästchen „download ocr text ( … )“ automatisch ein Haken gesetzt. Ausgewählt werden kann auch die Auflösung einzelner Seiten, was bei Abbildungen von Vorteil sein kann. Als drittes wird „convert & merge images to pdf book“ markiert.
Nach dem Download erscheinen die Dateien im vorgegebenen Verzeichnis. Die png-Grafiken werden zusammengeführt und als pdf gespeichert.
OCR und Schriftarten
Abschließend noch ein paar kurze Worte zu OCR (optical character recognition). Um ein Pdf mit einem gescannten oder fotografierten Text nach Stichworten durchsuchen zu können oder in ein Schreibprogramm einzufügen, muss der Text als solcher erkannt worden sein. Insgesamt können drei Arten von Pdfs unterschieden werden.
- Digital created Pdfs: Mit Programmen wie Microsoft Word, Open Office etc. digital aus Texten erzeugte Files.
- Image only oder scanned Pdfs: Gescannte oder fotografierte Texte, die im jpg- oder tif-Format vorliegen und in das pdf-Format umgewandelt werden. Sie sind nicht durchsuchbar.
- Searchable Pdfs: Dokumente, deren Text wird mit Hilfe eines OCR-Programms erkannt und durchsuchbar gemacht wurde.
Die gescannten Dokumente liegen als Rastergraphiken vor. Vereinfacht gesagt, die gesamte Seite besteht aus einer Ansammlung von Bildpunkten. Die Aufgabe des OCR-Programms besteht nun darin, in diesen Punkten Buchstaben und (Satz-)Zeichen aufzufinden. Zunächst werden dabei Strukturen, wie Blöcke und Zeilen und dann einzelne Zeichen erkannt, indem diese mit hinterlegten Mustern verglichen werden. Das Ganze basiert also auf dem Prinzip der Musterkennung. Was die Texterkennung betrifft, so ist Adobe DC (früher Adobe Acrobat) sicher immer noch führend im Bereich des OCR-Editorial, aber mit einem Preis von 250 Euro im Jahr sehr teuer. Auch andere Hersteller sind im Bereich der Texterkennung sehr empfehlenswert, wie etwa eine Untersuchung der Stiftung Warentest zeigt. Zur Erkennung von Frakturschrift liegen mittlerweile eine Reihe leistungsstarker, open source Programme vor. Zu nennen sind etwa Transkribus und Tesseract mit dem Frontend gImageReader. Am Rande sei bemerkt, dass sich mit den beiden Programmen auch ältere Handschriften bearbeiten lassen. Da wir jede Menge Rechungsbücher, Quittungen, Zahlungsanweisungen und ähnliches besitzen, ist der Einsatz dieser Software auch für den Numismatiker und Geldhistoriker zur Erstellung einer Umschrift sehr interessant.
Für Hinweise, Unterstützung und Hilfestellung bei der Erstellung dieses Tutorials danke ich Anke Matthes (Hannover). (uw)
 Hier können Sie das Tutorial als layoutetes Pdf herunterladen.
Hier können Sie das Tutorial als layoutetes Pdf herunterladen.
